By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.
Customer survey: How much did it cost to build your CSV importer in-house?
How much does it cost to build a CSV importer? OneSchema surveyed engineering teams at SaaS startups who have built CSV importers in-house and found they spent 3-6 months with a team of ~2 engineers. The estimated launch cost was $100,000 with an additional $75,000 of annual maintenance costs.
OneSchema surveyed engineering teams at SaaS startups who have built CSV importers in-house
Surveyed engineering teams spent 3-6 months with a team of ~2 engineers to launch CSV import, a 2x increase over projected build times of 1-3 months
The estimated launch cost is $100,000 with an additional $75,000 of annual maintenance costs
If you’re thinking about building a CSV importer, you’re probably facing a build versus buy decision - weighing the time of your team to build and maintain a custom solution over purchasing and implementing a 3rd party tool.
We surveyed companies who have launched their own in-house CSV importers to understand the cost & engineering time investment (hint: typically 3-6 months). This comprehensive guide will help you understand the resources needed to both build and maintain an in-house CSV Importer so you can make an informed build vs. buy decision.
How much does it cost to build a CSV importer?
The build versus buy formula
In a build-vs-buy decision, the formula for estimating build cost is the sum of:
Cost of initial build designing, building, iterating on, and testing initial feature launch
Cost of maintenance bugfixes, adaptive maintenance, performance, and QA
Cost of adding features engineering cost of new features to accommodate product changes
Opportunity cost revenue opportunities blocked by other features your team could be investing in
Cost of a lower-quality solution cost of launching a feature without the robustness and additional features of a 3P solution
Here’s an in-depth breakdown of each of these costs for a CSV import solution:
Initial build time
OneSchema’s survey of SaaS companies found the average time to launch CSV import (from project kickoff to launch) is 3-6 months for a team of ~2 engineers, for an average estimated build cost of $100,000. Most teams required both a front-end and back-end engineer to launch their CSV importer. PM and design typically provided substantial contributions.
The longest build times were multi-year projects for teams requiring numerous advanced features and frequently changing requirements.
Launch timelines were as short as a month for teams with very simple needs.
Importers used for critical workflows (such as customer onboarding or recurring data refresh) required substantially more investment than importers used for internal or occasionally used workflows.
Across surveyed engineering teams who built in-house importers, the core steps to launching a basic CSV importer are:
The 7 key steps to launching a CSV importer
Design the UI
Implement CSV parsing (including edge case management)
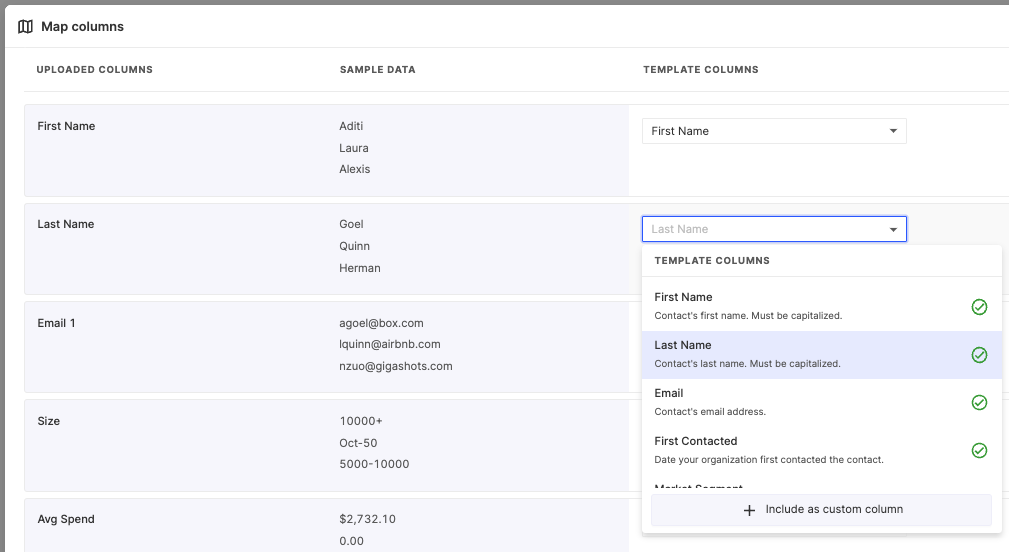
Build a UI experience for mapping
Build a UI experience for communicating errors to users and resolving errors in data
Write backend code to validate data
Configure endpoints to receive data
QA, launch a beta version, and iterate until the feature is customer-ready
Engineering teams frequently highlighted unforeseeable complexities that arose right before or immediately after product launch. Unanticipated roadblocks frequently derail production timelines and dependent feature launches.
Engineers like Lior Harel, founder of Staircase AI, shared that at his previous company the initial scoped CSV import launch timeline was 1 month, but the project ended up dragging out for over 1-year. “Edge cases like undo and supporting the long tail of date formats made the build feel endless,” said Harel.
Cost to Maintain
The more complex the importer and features you choose to build, the more maintenance it will likely need to support smooth, continued use. Surveyed companies found CSV importer maintenance to be about 75% of the initial build cost, for a total annual cost of $75,000 in engineering and QA costs, excluding customer support costs.
With CSV import, there were 4 main categories of maintenance that took up the engineering time after the initial build.
Maintaining the importer involves cycling through bugfixes, adaptive maintenance, improving performance, and QA.
Bugfixes: Engineering teams found their CSV importers to be especially error-prone, as customers frequently upload new edge-case CSV files into the system. Improper imports lead to bad data getting uploaded into your system, typically requiring an engineer to manage the undo or bulk correct the customer’s data.
Adaptive Maintenance: In general, most teams found that the biggest cost of maintaining their importer resulted from changes to their database schema. Each new field of validation requires engineering team to update their CSV importer as well and add new validations. This is not the case with a tool like OneSchema, where all validations come out of the box, making database schema updates trivial. Migrating tech stacks also had substantial consequences for engineering teams. Adopting new technologies required overhauling existing infrastructure, instead of outsourcing adaptive updates to a 3P vendor.
Performance: As systems scale, so will the performance requirements of a CSV importer. Companies found that their naive approaches to improving performance, which typically started with loading, validating, and visualizing all of the spreadsheet data at once in memory, scaled drastically as spreadsheets approached thousands (or millions) of rows. Most needed validations to be done in parallel batches, especially if their results were to be displayed in a responsive UI. Adding the capability of visualizing all the spreadsheet data on the front-end necessitated caching and sampling in order to not keep renders fast and instantaneous, especially while scrolling. Companies also reported that supporting bulk edits such as find-and-replace added significant complexity – particularly if they trigger downstream validations that need a round trip to the database or a third-party data provider like Google Maps.
QA: For every surveyed company, CSVs became a permanent, large product surface for their team to QA. Because every spreadsheet uploaded from users looks different, robust testing is constantly required to ensure edge cases are always handled correctly. A large number of encodings, formats, and file sizes which require ongoing testing caused QA to cost a substantial amount of resources, especially for teams with imports that involved validating date formats.
Affinity.co was among the surveyed companies where maintenance costs ended up far higher than initial import. “Two years after we started building CSV import, we prioritized our 4th engineering project to add improvements,” said Rohan Sahai, Director of Engineering at Affinity.
“The first self-serve CSV importer built at Affinity led to more support tickets than any other part of our product. And because it was so challenging to display all of the specific errors that could break the import flow, customers would get esoteric error messages like ‘something is amiss’ whenever there was a missing comma, encoding issue, or a myriad of business-specific data formatting problems that led to downstream processing issues. Because of the critical onboarding flow that data importer powered, before long v1.5, v2, and v3 were prioritized, leading to multiple eng-years of work in iterating toward a robust importer experience.”
Cost of Adding Features
As their products add more functionality, teams also found that they had to continue dedicating engineering resources for developing additional CSV Importer features to support more complex data ingestion workflows.
Critical features such as "Find and Replace" are typically not included for in-house CSV importer builds
Adding these key features caused teams to continue working on their CSV Importer for months (or even years in many cases), past the initial build time. Total costs for adding new features were highly variable between product teams due to vastly product requirements.
Opportunity Cost
Launching new features typically unlocks revenue opportunities for sales and customer success teams, and allocating engineering resources to CSV import inevitably delays other important features by several months.
CSV import is not part of a company’s core competency. While it’s an important step for making customers successful, product and engineering teams have a long roadmap of higher priority initiatives that are inevitably delayed when building an in-house importer.
Companies that start with building a CSV Importer in-house often quickly find that they need a better solution because of user dropoff during onboarding and an influx of support tickets. For example, at Heron Data, they knew they needed a better solution, but, “taking months of time to build out a robust CSV importer was not an option given competing business priorities.” After implementing OneSchema, Heron was able to redirect their resources to their core product. “Now that we don’t have to worry about building and maintaining an in-house CSV Importer, we can focus on other areas to add value for our customers.” said Johannes Jaeckle, CEO of Heron Data.
Cost of a Lower-Quality Solution
When first launching a CSV importer, most companies pursue a relatively bare bones importer as launching 100% of the features needed to make the perfect experience takes more resources than they can allocate.
Surveyed companies reported that missing critical features in their initial scope, such as an editable preview pane, resulted in customers being significantly more likely to abandon their imports. Customers became far more likely to submit support tickets, driving up support costs.
CSV importers are typically used during customer onboarding, so teams should carefully consider the revenue cost of:
Delaying customer onboarding
Losing accounts during onboarding
Importing less / lower quality customer data during onboarding
For a surveyed fintech company, each imported CSV file can contain hundreds of thousands in transaction volume. “If a customer abandoned a sheet import, we’d miss out on our transaction fee for an entire set of transactions. We have done everything within our power to make sure CSV import is as smooth as possible.”
Should I build my own CSV importer?
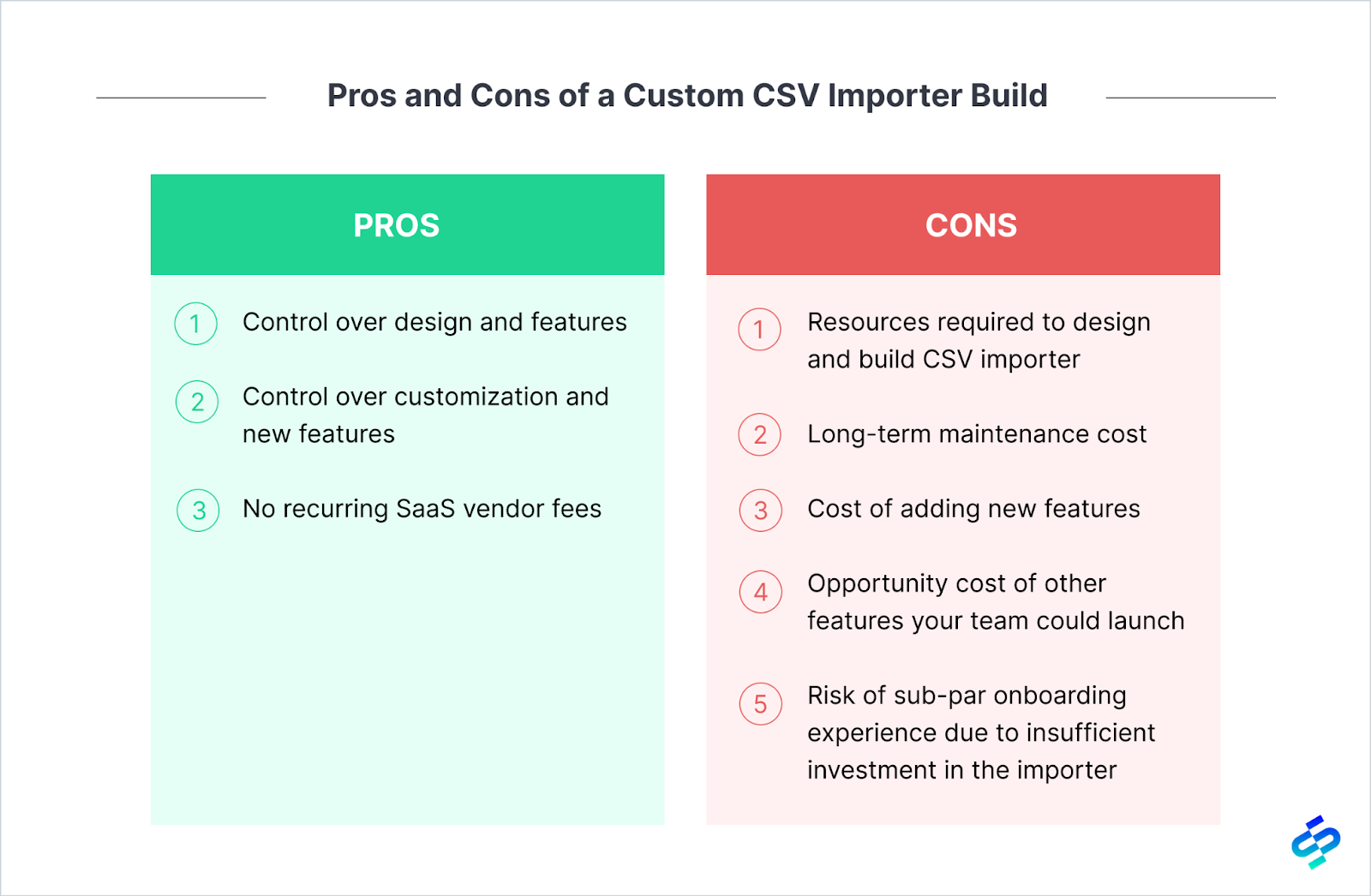
Now that you have a good understanding of how to evaluate the costs of building an in-house CSV Importer, let’s go over a high-level framework you can use to look at the pros and cons when deciding whether or not to pursue a custom build.
Opportunity cost of other features your team could launch
Risk of sub-par onboarding experience due to insufficient investment in the importer
Who should build their own CSV importer?
In an ideal world, time and cost aren’t an issue, and stakeholders, managers, designers, and developers would have deep planning conversations before implementing a new feature like CSV import. The reality is a new feature will likely be on a limited timeline, with only so many resources available to get it done.
For companies where CSV import is not on the critical customer path (supports an edge case workflow) investing in a quick, feature-light importer is a great option. The cost of missing features and bugs is low. If the CSV importer is part of critical workflows like customer onboarding or recurring data syncs, the cost of adopting a 3P solution is typically much lower than the cost to build in-house.
Customer survey: How much did it cost to build your CSV importer in-house?
How much does it cost to build a CSV importer? OneSchema surveyed engineering teams at SaaS startups who have built CSV importers in-house and found they spent 3-6 months with a team of ~2 engineers. The estimated launch cost was $100,000 with an additional $75,000 of annual maintenance costs.
OneSchema surveyed engineering teams at SaaS startups who have built CSV importers in-house
Surveyed engineering teams spent 3-6 months with a team of ~2 engineers to launch CSV import, a 2x increase over projected build times of 1-3 months
The estimated launch cost is $100,000 with an additional $75,000 of annual maintenance costs
If you’re thinking about building a CSV importer, you’re probably facing a build versus buy decision - weighing the time of your team to build and maintain a custom solution over purchasing and implementing a 3rd party tool.
We surveyed companies who have launched their own in-house CSV importers to understand the cost & engineering time investment (hint: typically 3-6 months). This comprehensive guide will help you understand the resources needed to both build and maintain an in-house CSV Importer so you can make an informed build vs. buy decision.
How much does it cost to build a CSV importer?
The build versus buy formula
In a build-vs-buy decision, the formula for estimating build cost is the sum of:
Cost of initial build designing, building, iterating on, and testing initial feature launch
Cost of maintenance bugfixes, adaptive maintenance, performance, and QA
Cost of adding features engineering cost of new features to accommodate product changes
Opportunity cost revenue opportunities blocked by other features your team could be investing in
Cost of a lower-quality solution cost of launching a feature without the robustness and additional features of a 3P solution
Here’s an in-depth breakdown of each of these costs for a CSV import solution:
Initial build time
OneSchema’s survey of SaaS companies found the average time to launch CSV import (from project kickoff to launch) is 3-6 months for a team of ~2 engineers, for an average estimated build cost of $100,000. Most teams required both a front-end and back-end engineer to launch their CSV importer. PM and design typically provided substantial contributions.
The longest build times were multi-year projects for teams requiring numerous advanced features and frequently changing requirements.
Launch timelines were as short as a month for teams with very simple needs.
Importers used for critical workflows (such as customer onboarding or recurring data refresh) required substantially more investment than importers used for internal or occasionally used workflows.
Across surveyed engineering teams who built in-house importers, the core steps to launching a basic CSV importer are:
The 7 key steps to launching a CSV importer
Design the UI
Implement CSV parsing (including edge case management)
Build a UI experience for mapping
Build a UI experience for communicating errors to users and resolving errors in data
Write backend code to validate data
Configure endpoints to receive data
QA, launch a beta version, and iterate until the feature is customer-ready
Engineering teams frequently highlighted unforeseeable complexities that arose right before or immediately after product launch. Unanticipated roadblocks frequently derail production timelines and dependent feature launches.
Engineers like Lior Harel, founder of Staircase AI, shared that at his previous company the initial scoped CSV import launch timeline was 1 month, but the project ended up dragging out for over 1-year. “Edge cases like undo and supporting the long tail of date formats made the build feel endless,” said Harel.
Cost to Maintain
The more complex the importer and features you choose to build, the more maintenance it will likely need to support smooth, continued use. Surveyed companies found CSV importer maintenance to be about 75% of the initial build cost, for a total annual cost of $75,000 in engineering and QA costs, excluding customer support costs.
With CSV import, there were 4 main categories of maintenance that took up the engineering time after the initial build.
Maintaining the importer involves cycling through bugfixes, adaptive maintenance, improving performance, and QA.
Bugfixes: Engineering teams found their CSV importers to be especially error-prone, as customers frequently upload new edge-case CSV files into the system. Improper imports lead to bad data getting uploaded into your system, typically requiring an engineer to manage the undo or bulk correct the customer’s data.
Adaptive Maintenance: In general, most teams found that the biggest cost of maintaining their importer resulted from changes to their database schema. Each new field of validation requires engineering team to update their CSV importer as well and add new validations. This is not the case with a tool like OneSchema, where all validations come out of the box, making database schema updates trivial. Migrating tech stacks also had substantial consequences for engineering teams. Adopting new technologies required overhauling existing infrastructure, instead of outsourcing adaptive updates to a 3P vendor.
Performance: As systems scale, so will the performance requirements of a CSV importer. Companies found that their naive approaches to improving performance, which typically started with loading, validating, and visualizing all of the spreadsheet data at once in memory, scaled drastically as spreadsheets approached thousands (or millions) of rows. Most needed validations to be done in parallel batches, especially if their results were to be displayed in a responsive UI. Adding the capability of visualizing all the spreadsheet data on the front-end necessitated caching and sampling in order to not keep renders fast and instantaneous, especially while scrolling. Companies also reported that supporting bulk edits such as find-and-replace added significant complexity – particularly if they trigger downstream validations that need a round trip to the database or a third-party data provider like Google Maps.
QA: For every surveyed company, CSVs became a permanent, large product surface for their team to QA. Because every spreadsheet uploaded from users looks different, robust testing is constantly required to ensure edge cases are always handled correctly. A large number of encodings, formats, and file sizes which require ongoing testing caused QA to cost a substantial amount of resources, especially for teams with imports that involved validating date formats.
Affinity.co was among the surveyed companies where maintenance costs ended up far higher than initial import. “Two years after we started building CSV import, we prioritized our 4th engineering project to add improvements,” said Rohan Sahai, Director of Engineering at Affinity.
“The first self-serve CSV importer built at Affinity led to more support tickets than any other part of our product. And because it was so challenging to display all of the specific errors that could break the import flow, customers would get esoteric error messages like ‘something is amiss’ whenever there was a missing comma, encoding issue, or a myriad of business-specific data formatting problems that led to downstream processing issues. Because of the critical onboarding flow that data importer powered, before long v1.5, v2, and v3 were prioritized, leading to multiple eng-years of work in iterating toward a robust importer experience.”
Cost of Adding Features
As their products add more functionality, teams also found that they had to continue dedicating engineering resources for developing additional CSV Importer features to support more complex data ingestion workflows.
Critical features such as "Find and Replace" are typically not included for in-house CSV importer builds
Adding these key features caused teams to continue working on their CSV Importer for months (or even years in many cases), past the initial build time. Total costs for adding new features were highly variable between product teams due to vastly product requirements.
Opportunity Cost
Launching new features typically unlocks revenue opportunities for sales and customer success teams, and allocating engineering resources to CSV import inevitably delays other important features by several months.
CSV import is not part of a company’s core competency. While it’s an important step for making customers successful, product and engineering teams have a long roadmap of higher priority initiatives that are inevitably delayed when building an in-house importer.
Companies that start with building a CSV Importer in-house often quickly find that they need a better solution because of user dropoff during onboarding and an influx of support tickets. For example, at Heron Data, they knew they needed a better solution, but, “taking months of time to build out a robust CSV importer was not an option given competing business priorities.” After implementing OneSchema, Heron was able to redirect their resources to their core product. “Now that we don’t have to worry about building and maintaining an in-house CSV Importer, we can focus on other areas to add value for our customers.” said Johannes Jaeckle, CEO of Heron Data.
Cost of a Lower-Quality Solution
When first launching a CSV importer, most companies pursue a relatively bare bones importer as launching 100% of the features needed to make the perfect experience takes more resources than they can allocate.
Surveyed companies reported that missing critical features in their initial scope, such as an editable preview pane, resulted in customers being significantly more likely to abandon their imports. Customers became far more likely to submit support tickets, driving up support costs.
CSV importers are typically used during customer onboarding, so teams should carefully consider the revenue cost of:
Delaying customer onboarding
Losing accounts during onboarding
Importing less / lower quality customer data during onboarding
For a surveyed fintech company, each imported CSV file can contain hundreds of thousands in transaction volume. “If a customer abandoned a sheet import, we’d miss out on our transaction fee for an entire set of transactions. We have done everything within our power to make sure CSV import is as smooth as possible.”
Should I build my own CSV importer?
Now that you have a good understanding of how to evaluate the costs of building an in-house CSV Importer, let’s go over a high-level framework you can use to look at the pros and cons when deciding whether or not to pursue a custom build.
Opportunity cost of other features your team could launch
Risk of sub-par onboarding experience due to insufficient investment in the importer
Who should build their own CSV importer?
In an ideal world, time and cost aren’t an issue, and stakeholders, managers, designers, and developers would have deep planning conversations before implementing a new feature like CSV import. The reality is a new feature will likely be on a limited timeline, with only so many resources available to get it done.
For companies where CSV import is not on the critical customer path (supports an edge case workflow) investing in a quick, feature-light importer is a great option. The cost of missing features and bugs is low. If the CSV importer is part of critical workflows like customer onboarding or recurring data syncs, the cost of adopting a 3P solution is typically much lower than the cost to build in-house.
OneSchema surveyed engineering teams at SaaS startups who have built CSV importers in-house
Surveyed engineering teams spent 3-6 months with a team of ~2 engineers to launch CSV import, a 2x increase over projected build times of 1-3 months
The estimated launch cost is $100,000 with an additional $75,000 of annual maintenance costs
If you’re thinking about building a CSV importer, you’re probably facing a build versus buy decision - weighing the time of your team to build and maintain a custom solution over purchasing and implementing a 3rd party tool.
We surveyed companies who have launched their own in-house CSV importers to understand the cost & engineering time investment (hint: typically 3-6 months). This comprehensive guide will help you understand the resources needed to both build and maintain an in-house CSV Importer so you can make an informed build vs. buy decision.
How much does it cost to build a CSV importer?
The build versus buy formula
In a build-vs-buy decision, the formula for estimating build cost is the sum of:
Cost of initial build designing, building, iterating on, and testing initial feature launch
Cost of maintenance bugfixes, adaptive maintenance, performance, and QA
Cost of adding features engineering cost of new features to accommodate product changes
Opportunity cost revenue opportunities blocked by other features your team could be investing in
Cost of a lower-quality solution cost of launching a feature without the robustness and additional features of a 3P solution
Here’s an in-depth breakdown of each of these costs for a CSV import solution:
Initial build time
OneSchema’s survey of SaaS companies found the average time to launch CSV import (from project kickoff to launch) is 3-6 months for a team of ~2 engineers, for an average estimated build cost of $100,000. Most teams required both a front-end and back-end engineer to launch their CSV importer. PM and design typically provided substantial contributions.
The longest build times were multi-year projects for teams requiring numerous advanced features and frequently changing requirements.
Launch timelines were as short as a month for teams with very simple needs.
Importers used for critical workflows (such as customer onboarding or recurring data refresh) required substantially more investment than importers used for internal or occasionally used workflows.
Across surveyed engineering teams who built in-house importers, the core steps to launching a basic CSV importer are:
The 7 key steps to launching a CSV importer
Design the UI
Implement CSV parsing (including edge case management)
Build a UI experience for mapping
Build a UI experience for communicating errors to users and resolving errors in data
Write backend code to validate data
Configure endpoints to receive data
QA, launch a beta version, and iterate until the feature is customer-ready
Engineering teams frequently highlighted unforeseeable complexities that arose right before or immediately after product launch. Unanticipated roadblocks frequently derail production timelines and dependent feature launches.
Engineers like Lior Harel, founder of Staircase AI, shared that at his previous company the initial scoped CSV import launch timeline was 1 month, but the project ended up dragging out for over 1-year. “Edge cases like undo and supporting the long tail of date formats made the build feel endless,” said Harel.
Cost to Maintain
The more complex the importer and features you choose to build, the more maintenance it will likely need to support smooth, continued use. Surveyed companies found CSV importer maintenance to be about 75% of the initial build cost, for a total annual cost of $75,000 in engineering and QA costs, excluding customer support costs.
With CSV import, there were 4 main categories of maintenance that took up the engineering time after the initial build.
Maintaining the importer involves cycling through bugfixes, adaptive maintenance, improving performance, and QA.
Bugfixes: Engineering teams found their CSV importers to be especially error-prone, as customers frequently upload new edge-case CSV files into the system. Improper imports lead to bad data getting uploaded into your system, typically requiring an engineer to manage the undo or bulk correct the customer’s data.
Adaptive Maintenance: In general, most teams found that the biggest cost of maintaining their importer resulted from changes to their database schema. Each new field of validation requires engineering team to update their CSV importer as well and add new validations. This is not the case with a tool like OneSchema, where all validations come out of the box, making database schema updates trivial. Migrating tech stacks also had substantial consequences for engineering teams. Adopting new technologies required overhauling existing infrastructure, instead of outsourcing adaptive updates to a 3P vendor.
Performance: As systems scale, so will the performance requirements of a CSV importer. Companies found that their naive approaches to improving performance, which typically started with loading, validating, and visualizing all of the spreadsheet data at once in memory, scaled drastically as spreadsheets approached thousands (or millions) of rows. Most needed validations to be done in parallel batches, especially if their results were to be displayed in a responsive UI. Adding the capability of visualizing all the spreadsheet data on the front-end necessitated caching and sampling in order to not keep renders fast and instantaneous, especially while scrolling. Companies also reported that supporting bulk edits such as find-and-replace added significant complexity – particularly if they trigger downstream validations that need a round trip to the database or a third-party data provider like Google Maps.
QA: For every surveyed company, CSVs became a permanent, large product surface for their team to QA. Because every spreadsheet uploaded from users looks different, robust testing is constantly required to ensure edge cases are always handled correctly. A large number of encodings, formats, and file sizes which require ongoing testing caused QA to cost a substantial amount of resources, especially for teams with imports that involved validating date formats.
Affinity.co was among the surveyed companies where maintenance costs ended up far higher than initial import. “Two years after we started building CSV import, we prioritized our 4th engineering project to add improvements,” said Rohan Sahai, Director of Engineering at Affinity.
“The first self-serve CSV importer built at Affinity led to more support tickets than any other part of our product. And because it was so challenging to display all of the specific errors that could break the import flow, customers would get esoteric error messages like ‘something is amiss’ whenever there was a missing comma, encoding issue, or a myriad of business-specific data formatting problems that led to downstream processing issues. Because of the critical onboarding flow that data importer powered, before long v1.5, v2, and v3 were prioritized, leading to multiple eng-years of work in iterating toward a robust importer experience.”
Cost of Adding Features
As their products add more functionality, teams also found that they had to continue dedicating engineering resources for developing additional CSV Importer features to support more complex data ingestion workflows.
Critical features such as "Find and Replace" are typically not included for in-house CSV importer builds
Adding these key features caused teams to continue working on their CSV Importer for months (or even years in many cases), past the initial build time. Total costs for adding new features were highly variable between product teams due to vastly product requirements.
Opportunity Cost
Launching new features typically unlocks revenue opportunities for sales and customer success teams, and allocating engineering resources to CSV import inevitably delays other important features by several months.
CSV import is not part of a company’s core competency. While it’s an important step for making customers successful, product and engineering teams have a long roadmap of higher priority initiatives that are inevitably delayed when building an in-house importer.
Companies that start with building a CSV Importer in-house often quickly find that they need a better solution because of user dropoff during onboarding and an influx of support tickets. For example, at Heron Data, they knew they needed a better solution, but, “taking months of time to build out a robust CSV importer was not an option given competing business priorities.” After implementing OneSchema, Heron was able to redirect their resources to their core product. “Now that we don’t have to worry about building and maintaining an in-house CSV Importer, we can focus on other areas to add value for our customers.” said Johannes Jaeckle, CEO of Heron Data.
Cost of a Lower-Quality Solution
When first launching a CSV importer, most companies pursue a relatively bare bones importer as launching 100% of the features needed to make the perfect experience takes more resources than they can allocate.
Surveyed companies reported that missing critical features in their initial scope, such as an editable preview pane, resulted in customers being significantly more likely to abandon their imports. Customers became far more likely to submit support tickets, driving up support costs.
CSV importers are typically used during customer onboarding, so teams should carefully consider the revenue cost of:
Delaying customer onboarding
Losing accounts during onboarding
Importing less / lower quality customer data during onboarding
For a surveyed fintech company, each imported CSV file can contain hundreds of thousands in transaction volume. “If a customer abandoned a sheet import, we’d miss out on our transaction fee for an entire set of transactions. We have done everything within our power to make sure CSV import is as smooth as possible.”
Should I build my own CSV importer?
Now that you have a good understanding of how to evaluate the costs of building an in-house CSV Importer, let’s go over a high-level framework you can use to look at the pros and cons when deciding whether or not to pursue a custom build.
Opportunity cost of other features your team could launch
Risk of sub-par onboarding experience due to insufficient investment in the importer
Who should build their own CSV importer?
In an ideal world, time and cost aren’t an issue, and stakeholders, managers, designers, and developers would have deep planning conversations before implementing a new feature like CSV import. The reality is a new feature will likely be on a limited timeline, with only so many resources available to get it done.
For companies where CSV import is not on the critical customer path (supports an edge case workflow) investing in a quick, feature-light importer is a great option. The cost of missing features and bugs is low. If the CSV importer is part of critical workflows like customer onboarding or recurring data syncs, the cost of adopting a 3P solution is typically much lower than the cost to build in-house.

.png)




.png)


